

We’ve developed a tool (non generative AI Agent) to summarise concepts explained in Norvig and Russel’s Artificial Intelligence, A Modern Approach (2nd ed). Credit also goes to the University of London (Goldsmiths) for the data and concepts.
It’s a conceptual knowledge model encoded in a machine-processable format in an RDF (resource description framework).
Before building advanced generative AI agents (often considered black boxes), it’s essential to grasp the foundational principles of traditional AI. Therefore, we have embraced an accessible approach to developing an AI agent for drug discovery, ensuring its transparency, interpretability and explainability from the ground up.
AI is the study of agents that receive precepts from the environment and perform actions. An agent is anything that perceives its environment through sensors and acts upon that environment through actuators.
A human agent has eyes, ears, and other organs for sensors and hands, legs, mouth, and other body parts for actuators. A robotic agent might have cameras, infrared range finders for sensors, and various actuator motors. A software agent receives keystrokes, file contents, and network packets as sensory inputs and acts on the environment by displaying on the screen, writing files, and sending network packets. We will assume that every agent can perceive its actions (but only sometimes the effects).
We use percept to refer to the agent’s perceptual inputs at any given instant. An agent’s percept sequence is the complete history of everything the agent has ever perceived. In general, an agent’s choice of action at any given instant can depend on the entire percept sequence observed to date. If we can specify the agent’s choice of action for every possible percept sequence, then we have said more or less everything there is to say about the agent. Mathematically, we say that an agent’s behaviour is described by the agent function that maps any given percept sequence to an action.
Why These AI Agents Could Be Useful in Digital Healthcare
AI agents have been utilised in laboratory research to automate processes. They can automate repetitive tasks such as data collection, analysis, and synthesis, allowing researchers to focus on higher-level tasks and creativity. The pandemic caused widespread interruptions and abandonment of traditional laboratory operations, leading researchers to rely increasingly on AI and automation to maintain progress in scientific research.
We have already discussed drug discovery’s game-changing abilities and the challenges ahead. Let’s review the specific AI agents involved in developing our multi-agent system, the AI Agent Drug Discovery tool.
Knowledge-Based Agents
Humans seem to know things, and what they know helps them do things. These are not empty statements. They make strong claims about how humans’ intelligence is achieved—not by purely reflex mechanisms but by reasoning processes that operate on internal representations of knowledge. In AI, this approach to intelligence is embodied in knowledge-based agents.
The knowledge agent in drug discovery is responsible for managing and extracting relevant information from the RDF file ontology. It ensures the reasoning agent has accurate and comprehensive data to generate hypotheses and that the planning and lab agents receive updated and relevant facts for experimental procedures.
How We Deployed Our Knowledge Agent
Our knowledge Agent (and all agents and associated files) was developed in VS Code and is a tool designed to read and understand a specific file (called an RDF file) that contains information organised in a particular way (ontology). This file is located in a folder containing data in a .owl format. The main job of this tool is to automatically extract useful information about different chemicals from this file and then create a list of these facts, which is stored in another file called facts.py (Python script).
The knowledge_model.py script reads the RDF file and shows all the triplets (sets of three related pieces of information: subjects, predicates, and objects). You can see these triplets by viewing option 1 in our tool below. The facts listed in facts.py are manually added and not automatically retrieved from the RDF file.
Role: Stores and retrieves information about chemical compounds, biological activities, and known interactions.
Data Sources:
- Chemical properties (e.g., molecular weight, hydrogen bond donors/acceptors).
- Biological activities (e.g., IC50 values, efficacy).
- Previous experimental results.
Data (table)
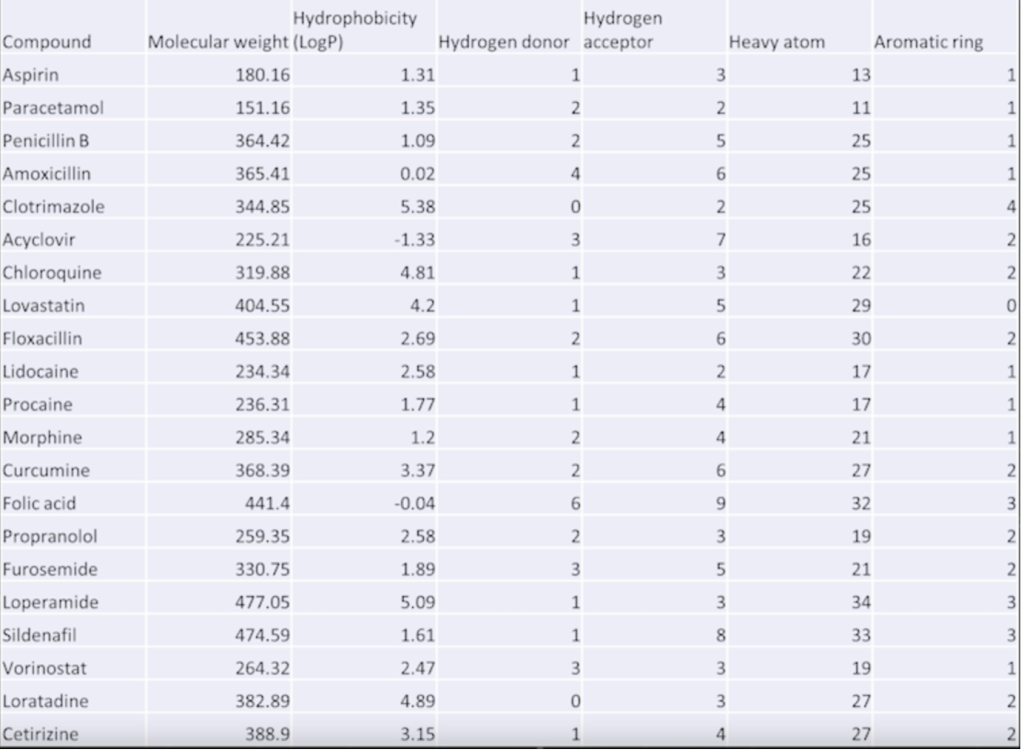
Refer to Output #1 in the notebook below:
Displays the raw data parsed from the RDF file (using Python), [chemical, molecular_weight]·
Displays the adjusted data parsed from the RDF file, [chemical, molecular weight, size, possible drug candidate]
Reasoning Agent
A reasoning agent is an AI system that uses logic and inference to conclude from known facts and rules. This agent can make decisions, solve problems, and generate new knowledge by applying deductive reasoning techniques. It typically operates on a knowledge base (such as above) containing information about the domain and uses algorithms to infer new information or make decisions based on the input data.
The reasoning agent in drug discovery generates hypotheses and draws conclusions based on available data and established rules. It uses logical inference and abductive reasoning to propose potential drug candidates and suggest experimental pathways.
How We Deployed Our Reasoning Agent
Role: Makes logical inferences based on data from the knowledge base to identify potential drug candidates.
Functions:
- Hypothesis Generation: Uses the rules.py script to propose which compounds will likely be effective drugs based on their properties
- Inference: Determines the implications of specific chemical properties on biological activity
Conceptual Model of Our Domain (Blue reflects the structure of the table, and yellow reflects the additional facts):

For example, small molecules with a low molecular weight are more likely to have an effect when administered to our bodies. In contrast, large molecules are generally less likely to penetrate cell membranes without assistance. This particular knowledge is not in the table (data). Machine learning can discover or predict this knowledge with enough suitable data. However, we don’t require machine learning for this particular task, as it’s common domain knowledge.
I’ll also add the downside of using machine learning for this task. Adding new information to improve learning may prove difficult in a real complex domain with many hierarchical layers, complex connections, assumptions, and restrictions, and thus, it is harder to represent as a table or database. Hence, conventional machine learning approaches would miss most of the knowledge and are unsuitable for the task. Thus, logic is more suitable for capturing this knowledge and reasoning with it.
Abductive reasoning is often preferred in drug discovery because it is well-suited to generating plausible hypotheses from incomplete data, is problem-solving oriented, and encourages the exploration of novel ideas. This makes it a powerful tool for identifying new drug candidates and understanding complex biological systems, where traditional inductive reasoning might fall short due to data limitations and the need for innovative approaches.
Refer to Output #2 from the notebook below, which displays the rules and facts and uses logic to derive potential drug candidates.
Planning Agent
A planning agent is an AI system designed to devise actions to achieve specific goals. This agent takes the current state of the world and a set of desired outcomes, then determines the necessary steps to transition from the current state to the desired goal state.
In drug discovery, a planning agent might use information from a knowledge base about chemical properties and biological activities and reasoning about potential interactions and outcomes to plan a series of experiments or synthesis steps to create a new drug candidate.
How We Deployed Our Planning Agent
Role: The planning agent is responsible for organising and managing the detailed schedules, task allocations, available equipment and its functionality, available materials, resource management, and rules for experiment planning (knowledge base) necessary to execute experiments in the drug discovery process.
Functions:
- Task Breakdown:
- Decompose the experimental process into manageable tasks such as reagent preparation, equipment setup, assay execution, and data analysis.
- Scheduling:
- Develop a timeline for these tasks, ensuring proper sequencing and respecting dependencies among tasks.
- Resource Allocation:
- Assign necessary resources to each task, including lab personnel, equipment, and materials, ensuring optimal use of available resources.
- Chemical Availability Check:
- Ensure that if a chemical from the hypotheses list is not available in the list of materials, the protocol generation is rejected. This is crucial for the AI Agent to produce a valid protocol, which requires all listed chemical hypotheses to be present in the materials list.
- For example, if “Lidocaine” is removed from the list of materials in the materials.py script, the planning agent should output an informative message and reject the protocol generation. If Lidocaine is present, we proceed with the protocol generation.
Planning agents can produce experimental protocols to test hypotheses formulated by the hypothesis generator. Experimental planning is a highly demanding task, requiring sophisticated reasoning over experiment knowledge. The planning agents can conduct thousands of experiments in parallel, testing many hypotheses simultaneously. Human scientists could be more efficient in parallel tasking but are better than planning agents at the high-level planning of experiments.
Refer to Output #3 in the notebook below, which runs through all testable hypotheses and planning steps and translates the theory into an experimental protocol.
Lab Agent
The lab agent is responsible for conducting experiments, collecting data, and validating hypotheses generated by the reasoning agent. This agent performs practical and simulated laboratory tasks to verify the feasibility and effectiveness of proposed drug candidates. The lab agent helps bridge the gap between theoretical models and practical applications by integrating real-world experimental data with computational predictions.
How We Deployed Our Lab Agent
Role: The lab agent is responsible for executing experimental protocols based on hypotheses generated by the reasoning agent and plans created by the planning agent. It ensures that experiments are conducted accurately, results are recorded and analysed, and updates are provided to the knowledge base for further analysis.
Functions:
- Protocol Execution:
- Execute experimental protocols provided by the planning agent.
- Result Recording:
- Record the results of experiments in a structured format.
- Data Analysis:
- Analyse experimental data to derive meaningful insights and conclusions.
- Feedback Loop:
- Update the knowledge agent with experimental results for further hypothesis generation and refinement.
- Communication with Planning Agent:
- Ensure all required materials and chemicals are available and provide feedback if any need be added.
Refer to Output #4 in the notebook below, which generates the experimental results table from the protocol.
Analysis Agent
An analysis agent is a type of agent designed to examine and interpret information or situations. It focuses on processing data to understand patterns, make predictions, or derive insights. This contrasts with other agents that may focus more on acting or making decisions based on their environment. Essentially, an analysis agent’s primary function is to analyse and make sense of data rather than to interact directly with the environment or execute tasks.
How We Deployed Our Results Analysis Agent
Role:
Data Filter and Selection – The primary role of this analysis agent is to sift through experimental results data to identify and select chemicals with potency values above a certain threshold, indicating their potential as viable drug candidates. This involves processing and interpreting data to make informed decisions about which chemicals should advance to the next stage of drug discovery.
Functions of the Analysis Agent:
- Data Reading:
- Function: Open and read the file’s contents located at /output/experimental_results.txt.
- Purpose: To access the experimental results data necessary for analysis.
- Data Parsing:
- Function: Parse the data using Python to extract relevant columns, particularly the chemical identifiers and their associated potency values.
- Purpose: To transform the raw data into a structured format suitable for analysis.
- Data Filtering:
- Function: Apply a filter to the parsed data to select only those chemicals with potency values above the threshold (e.g., 0.5).
- Purpose: To identify and isolate chemicals that meet the criteria for further investigation.
- Data Output:
- Function: Output the selected chemicals into a readable format (e.g., print them to the console or save to a new file).
- Purpose: To provide a clear and actionable list of chemicals that are considered for the next stage in drug development.
Statistical Analysis
There wasn’t adequate data to perform machine learning. Hence, statistical analysis was performed.
Our simple statistical analysis involved the following steps:
- Modify the code inside analysis.py script
- Read the data from the ‘/output/ experimental_results.txt’ file and store it in a suitable data structure (e.g. nested list)
- Filter the data not to include “Morphine” and its potency measurements (Morphine was added as a control chemical)
- Calculate the potency mean for each chemical in the data structure
- Use the mean to determine if such a chemical should be selected (mean > 0.5) or not
- Print the chosen chemicals in the drug discovery table
The analysis agent ensures that only chemicals with sufficient potency are moved forward in the drug discovery process. Its functions involve reading data, parsing and filtering it based on specified criteria, and providing the results in a usable format. This approach leverages statistical analysis to make data-driven decisions, enhancing the efficiency and effectiveness of the drug development pipeline.
Refer to Output #5 in the notebook below (the last step in our tool), where the analysis agent implements a valid method for drug discovery and makes inferences about possible drug candidates.