
TLDR
TWIN‑GPT is a research‑only digital twin engine that uses large language models to create patient‑specific virtual trial participants from longitudinal clinical data, sitting upstream of trial design and analysis.
Its proposed value is supporting smarter RCT design and interpretation by simulating individual trajectories under alternative arms, eligibility criteria, and dosing strategies, especially in data‑sparse settings.
Early evidence is limited to retrospective studies showing improved outcome prediction and high‑fidelity synthetic trajectories versus standard ML, with no prospective trials or regulatory use yet.
Evaluation should focus on data quality and harmonisation, external validation, bias and representation of under‑served groups, and how digital‑twin outputs are governed within existing model‑risk and trial‑governance frameworks.
For now, TWIN‑GPT‑style approaches are best viewed as exploratory decision‑support for design and scenario testing, not as a replacement for RCTs or a source of standalone regulatory evidence.
This article explores an emerging, next‑generation clinical AI concept that is not yet available for purchase or routine commercial use.
Randomised controlled trials (RCTs) are still the gold standard for testing new therapies, but they’re also one of the weakest links in the life‑sciences pipeline. They’re slow, expensive, and often struggle to recruit on time [1]. On top of that, many trials don’t look much like real‑world practice: older adults, people with multiple conditions, and minority populations are frequently screened out by strict inclusion and exclusion criteria [2, 3].
Sponsors and investigators are under growing pressure to accelerate development, reduce participant burden, and answer more granular questions about how treatments work in specific subgroups [3]. Traditional statistics and standard machine‑learning models help a bit, but they usually sit “after the fact”: they analyse data once it’s collected rather than generating rich, patient‑specific simulations before a study even starts [4].
That’s where digital twins come in. In other industries, a digital twin is a dynamic virtual replica of a physical asset that you can probe, stress‑test, and optimise [4, 5]. In healthcare and clinical research, a digital twin is a data‑driven or mechanistic model that mimics an individual patient, so teams can explore “what if?” scenarios without exposing real people to every possible risk [3]. Early work suggests these twins could reshape how trials are designed, analysed, and possibly adapted in real time [5].
If you’re a sceptical manager or steering‑committee member, this isn’t about replacing trials. It’s about giving your teams better tools to design smarter, fairer, more informative studies.
Meet TWIN‑GPT: a digital twin engine for trials
One of the most interesting early‑stage examples is TWIN‑GPT, a research‑only framework that uses large language models (LLMs) to create personalised digital twins of clinical trial participants [1]. Instead of building a bespoke mechanistic model for each disease, TWIN‑GPT fine‑tunes a general‑purpose LLM on longitudinal trial datasets, learning how demographics, lab values, interventions, and outcomes evolve together over time [1].
In plain English, TWIN‑GPT takes each participant’s story, baseline characteristics, visit‑by‑visit measurements, treatment assignments, and turns it into a sequence the model can understand. It then generates a virtual “twin” of that person that you can run forward under different treatment arms, dose schedules, or eligibility choices, simulating how their trial journey might unfold [1]. Instead of a trial being a static comparison of two arms, you get a hybrid physical‑virtual experiment, enriched by thousands of plausible trajectories that never actually happened but are statistically grounded in observed data [1, 2].
The researchers behind TWIN‑GPT report that, on historical trial data, these twins can predict outcomes more accurately than conventional machine‑learning baselines, especially when data are sparse [1]. They also show that synthetic trajectories generated by the model closely resemble those of the real patients it was trained on, which is essential if you ever want to use digital twins in virtual control arms or design optimisation [1, 5].
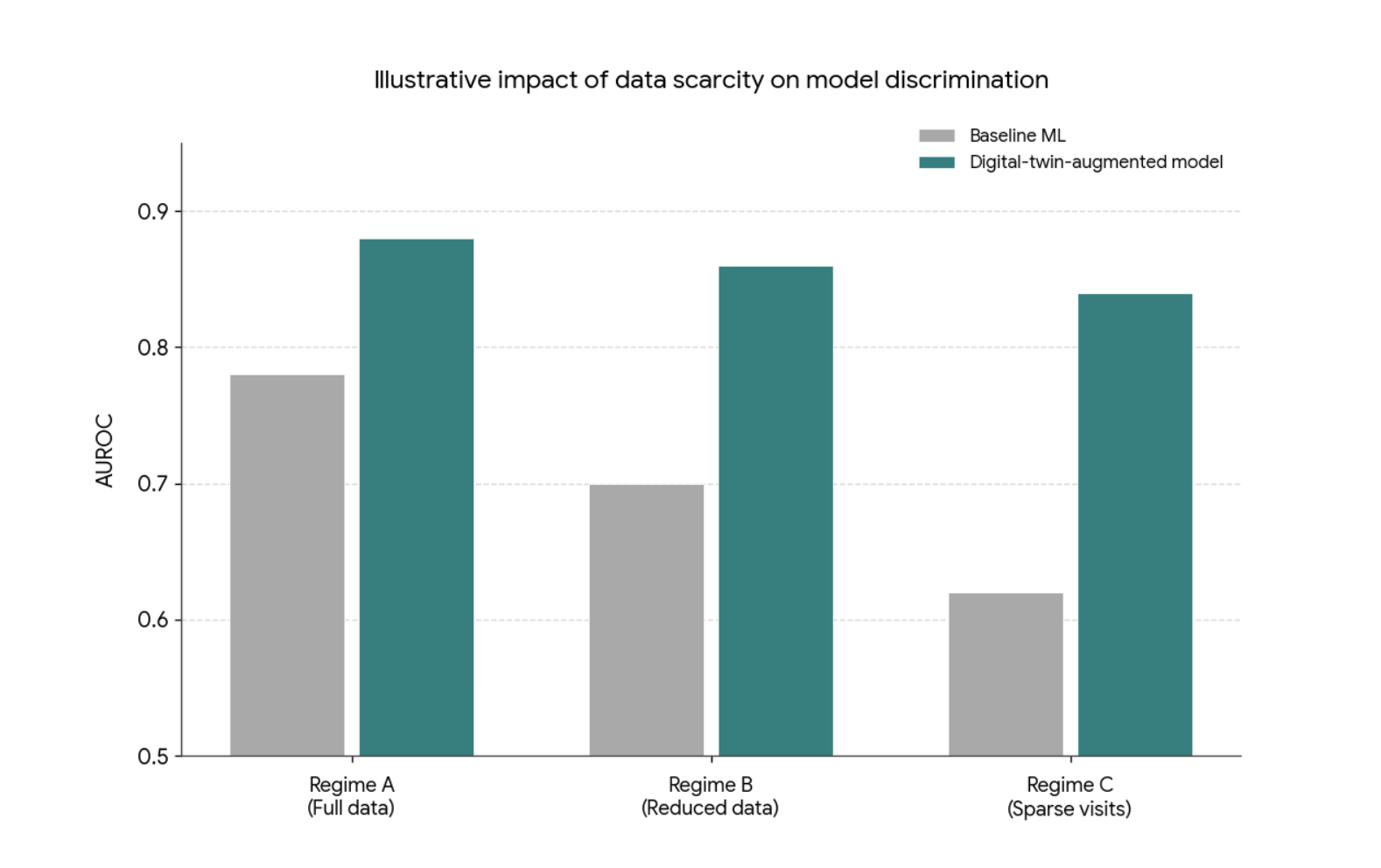
Figure 1: Conceptual illustration of how a digital‑twin‑augmented model can remain more robust to data scarcity than conventional machine‑learning baselines. As available trial data decrease (from full data to sparse visits), baseline models typically lose discriminative performance, while digital‑twin‑based approaches are intended to degrade more slowly. This schematic is illustrative only and does not reproduce specific results from Wang et al., “Digital Twins for Clinical Trials via Large Language Model” (arXiv:2404.01273). It compares AUROC for two series: Baseline ML (neutral grey), which shows a visible decline as data become scarcer, and a digital‑twin‑augmented model (teal), which starts higher and declines more slowly, reflecting the general behaviour reported in the paper
As the authors put it,
“TWIN‑GPT can generate high‑fidelity trial data that closely approximates specific patients, aiding in more accurate result predictions in data‑scarce situations” [1].
That’s exactly the sort of promise that should get a steering committee’s attention.
From trial data to personalised virtual patients
To see why this matters for your organisation, it helps to understand how TWIN‑GPT builds a twin. Clinical trial datasets are rich but messy: they combine baseline variables, repeated measures, adverse events, and outcomes across multiple visits. TWIN‑GPT converts this complexity into a tokenised sequence, preserving information about time, treatment, and context so the LLM can learn how patients typically evolve under different conditions [1].
For each participant, the model conditions on their own history, age, comorbidities, lab trends, prior events. Plus trial‑level details like arm assignment and visit schedule [1, 9]. It then generates likely future states step by step, sampling from a data‑driven joint distribution over patient trajectories. Conceptually, this isn’t far from mechanistic twins in immuno‑oncology, which fit individual patients to biological models and then generate new virtual patients by sampling from a latent parameter space [7]. TWIN‑GPT simply takes a more data‑centric route, relying on patterns in trial datasets rather than explicit biological equations [1].
From a practical perspective, this is attractive. Sponsors and academic centres already sit on huge amounts of underused trial data. A twin engine tuned to those datasets could, in principle, be applied across multiple trials and indications, provided the inputs are well curated and harmonised [4, 5]. For digital health leaders, data‑science heads, and clinical operations teams, the challenge isn’t the concept; it’s the plumbing: getting high‑quality, tokenisable data out of existing EDC or CDMS platforms and into a secure, auditable modelling environment.
If your organisation is thinking ahead, this is the sort of data and governance groundwork you can start laying now, before tools like TWIN‑GPT reach pilot‑ready maturity.
What the early evidence actually shows
Because TWIN‑GPT is still at the preprint stage, the evidence base is early, so it’s right to be cautious. That said, the initial results are promising enough to warrant serious attention [1].
In their experiments, the developers ran TWIN‑GPT on historical trial datasets and benchmarked it against established prediction models. They report statistically significant gains in predicting key outcomes, particularly when data are limited or irregular, suggesting the model’s ability to capture rich temporal patterns offers real advantages over standard approaches [1].
Just as important, the synthetic twins look like their real counterparts. The authors show that distributions of key variables, such as lab values and outcome measures, line up closely between real and virtual participants, at least within the datasets studied [1]. That level of fidelity is critical if digital twins are ever going to support virtual control arms or sensitivity analyses in ways regulators and clinicians can trust [2].
A 2024 perspective summarises the potential succinctly:
“AI‑generated digital twins of clinical trial participants could provide an ethically attractive, scalable way to explore treatment effects in populations currently excluded from trials” [2].
However, there are no published prospective pilots yet where TWIN‑GPT runs alongside a live trial, and there’s no sign of broad commercial deployment. For managers and governance boards, that means two things: don’t oversell it internally. But don’t ignore it either. The next wave of work will need to move from retrospective metrics to carefully governed pilots that test how twin‑driven insights actually influence design and interpretation [3, 9].
Beyond traditional RCTs: what changes in practice?
To see why this matters for your future portfolio, compare a TWIN‑GPT‑style setup with the trials you run today. In a typical RCT, design decisions, eligibility criteria, endpoints, and sample size are based on historical data, expert opinion, and relatively simple simulations. AI, where it’s used, often supports site selection, recruitment prediction, or risk‑based monitoring rather than individual‑level outcome simulation [3].
Digital twin frameworks aim to move simulation closer to clinical reality. Instead of assuming a generic “average patient”, they let investigators ask more concrete questions, such as:
How would different types of patients fare under alternative eligibility rules? [3, 6]
What if adherence is lower than expected in a particular subgroup? [1, 8]
How robust are the results if we include, rather than exclude, patients with specific comorbidities? [2, 6]
Recent work on digital‑twin‑enhanced RCTs outlines use cases like using twins to contextualise results for real‑world populations, test alternative designs, and explore dose or schedule changes without exposing real participants to every scenario [3, 8]. As one author notes,
“Digital twins can act as a bridge between randomised trial populations and the patients we actually see in practice” [3].
Here’s where TWIN‑GPT’s LLM core really matters. Once tuned to a domain, it can simulate a wide range of scenarios from the same data foundation, rather than needing a new mechanistic model for each “what‑if” question [1]. For trial designers and portfolio leads, that opens a more exploratory, iterative way of thinking about design—without abandoning regulatory rigour.
Diversity, inclusion, and equity: twin as mirror or distortion?
One of the strongest arguments you can take to a steering committee is around diversity and equity. Digital twins could help trials become more inclusive by simulating outcomes for groups that are currently missing from the evidence base [6]. For instance, you could use TWIN‑GPT‑style models to explore benefit–risk patterns in older multimorbid patients or historically under‑represented ethnic groups, then design more inclusive eligibility criteria from the outset [1, 6].
But there’s a big caveat: twins can only mirror the data they’re trained on. Many historical trials under‑represent the very groups we most want to learn about, and sometimes systematically exclude them [3, 6]. If TWIN‑GPT learns from those data without explicit correction, its synthetic patients may be poor stand‑ins, creating an illusion of inclusivity where there isn’t any.
A 2025 article on digital twins and diversity puts it bluntly: “Leveraging AI‑enabled digital twins without addressing existing data gaps could inadvertently widen, rather than close, disparities in evidence generation” [6].
For leadership teams, this is a key governance question: how will you audit data provenance, representation, and model behaviour to ensure digital twins contribute to fairer evidence generation, rather than baking in existing inequities? [9]
Risks, limitations, and governance questions you’ll be asked
If you propose exploring TWIN‑GPT‑like tools, you’ll face legitimate pushback. So, it’s worth having clear answers. Methodologically, TWIN‑GPT depends on the quality and consistency of historical trial data, which are often siloed, fragmented, and biased toward well‑resourced centres in high‑income countries [1, 4]. External validation across diverse datasets is still limited, and as a preprint, the work may not yet provide all the details needed for independent replication and auditing [1].
Operationally, integrating digital twins into trial workflows could disrupt established roles and responsibilities. Who’s accountable if a twin‑driven recommendation influences a design choice that leads to poorer outcomes or missed benefits? How should you explain the use of synthetic data to ethics committees and participants, especially if virtual control arms or smaller human cohorts are involved? [2, 9]
Regulators are moving cautiously but are clearly paying attention. Commentaries on AI‑generated digital twins suggest agencies are, for now, more comfortable using them as decision‑support rather than as primary evidence, and only where there’s transparent documentation, robust validation, and clearly defined roles [2, 9]. Broader frameworks for trustworthy medical AI, such as FUTURE‑AI and emerging medical digital‑twin governance proposals, stress data quality, bias control, transparency, robustness, and human oversight as non‑negotiable preconditions for deployment [9].
If you want your organisation to be ready, this is where you can start: data strategy, validation standards, model governance, and clear internal guidelines on where digital twin evidence can and can’t be used.
Where TWIN‑GPT sits in the broader digital twin ecosystem
Finally, it helps to frame TWIN‑GPT in the wider digital twin and virtual patient landscape. Oncology is already a hotbed for this work, with teams building dynamic digital twins to adapt treatment in real time, virtual patients to test immunotherapy strategies, and multi‑scale models that integrate tumour growth, pharmacokinetics, and patient‑level variables [7, 8, 10].
At the infrastructure level, the European EDITH Virtual Human Twin initiative is developing platforms and standards to combine organ‑specific twins into integrated virtual humans, targeting use cases in cancer, cardiovascular disease, intensive care, osteoporosis, and brain disorders [4, 9].
TWIN‑GPT sits in a distinctive niche inside this ecosystem. Instead of modelling a specific biological pathway in depth, it offers a flexible, data‑driven way to simulate whole‑patient trajectories across many trials, potentially acting as an overlay that connects disease‑specific twins, trial analytics, and decision‑support tools [1, 5]. For digital health leaders and trial sponsors, it makes sense to think of TWIN‑GPT as a bridge between traditional bio‑simulation and modern AI—a way to bring virtual patients into mainstream trial design without starting from scratch for every condition.
For teams monitoring developments in AI in healthcare and life sciences, HealthyData.Science provides independent explainers of emerging AI solutions in healthcare and approaches. Content is informed by practical project experience and research, helping teams build informed awareness and assess developments internally.
References
Wang Y, Fu T, Xu Y, Ma Z, Xu H, Du B, Lu Y, Gao H, Wu J, Chen J. TWIN-GPT: Digital Twins for Clinical Trials via Large Language Model. arXiv preprint arXiv:2404.01273. March 2024. (Later published in ACM Transactions on Multimedia Computing, Communications, and Applications, July 2024)
Vidovszky M, et al. Increasing acceptance of AI‑generated digital twins for clinical trials. Nature Medicine (Perspective). June 2024.
Akbarialiabad S, et al. Enhancing randomized clinical trials with digital twins. Journal of Clinical Epidemiology. February 2025.
Rudsari SR, et al. Digital twins in healthcare: a comprehensive review and future directions. Digital Health. January 2025.
Katsoulakis T, et al. Digital twins for health: a scoping review. npj Digital Medicine. May 2024.
Tubbs A, Alvarez Vazquez E. Digital twins in increasing diversity in clinical trials: A systematic review. Journal of Biomedical Informatics. August 2025.
Wang H, Arulraj T, Ippolito A, Popel AS. From virtual patients to digital twins in immuno‑oncology: lessons learned from mechanistic quantitative systems pharmacology modeling. Frontiers in Systems Biology. June 2024.
Karaman I, Sebin B. From data-driven cities to data-driven tumors: dynamic digital twins for adaptive oncology. Frontiers in Artificial Intelligence. July 2025.
Nadeem M, Kostic S, Dornhöfer M, Weber C, Fathi M. Medical digital twins: enabling precision medicine and beyond. Digital Health. January 2025.
Giansanti D, Morelli S. Exploring the Potential of Digital Twins in Cancer Treatment: A Narrative Review of Reviews. Journal of Clinical Medicine. May 2025.

Author: Stephen
Founder of HealthyData.Science · 20+ years in life sciences compliance & software validation · MSc in Data Science & Artificial Intelligence.